C/C++ 项目中的 DevOps 和持续集成挑战




现代软件开发和工程在过去十年中发生了发展。敏捷软件开发、持续集成 (CI)、持续部署或交付 (CD) 已成为主流实践。专业角色减少,而全栈工程师正在崛起。由于需要更快地发布更多版本,并在共同的纪律(DevOps)下进行,因此编码、构建和测试、发布、部署和监控比以往任何时候都更加紧密地联系在一起。
DevOps 的目标是改进软件流程、缩短上市时间、降低故障率、缩短发布周期,并减少从报告错误到最终部署并成功验证修复所需的时间。许多顶级科技公司能够每天将其生产系统持续部署数百次。这种响应能力正变得越来越必要:快速发布或消亡!
C 和 C++ 项目不仅是软件的支柱,也是整个 IT 行业的支柱:从操作系统、嵌入式系统、金融、研究、汽车、机器人、游戏等等。技术的快速发展、商业和科学的快速发展正在要求加快其流程。C 和 C++ 项目必须拥抱现代 DevOps 文化。
然而,也存在一些挑战需要面对。首先是与其他语言相比,**项目规模巨大**。在阅读了一篇关于 JavaScript 代码库因几万行代码而自称规模庞大的文章后,我针对 C 和 C++ 进行了一项(统计意义不大的)调查。一个 C 或 C++ 项目从 1000 万行代码开始被认为是大型项目。此类项目的编译时间可能比其他语言大几个数量级。
作为一种编译为原生机器码的语言,**应用程序二进制接口 (ABI) 不兼容性**也是一个大问题。其他语言,即使编译为字节码,也不会遇到此挑战。Rust 和 Go 这两种现代语言编译为原生代码怎么样?好吧,它们也不会真正遇到 ABI 不兼容性问题。例如,它们各自的包管理器,“Cargo” 和“goget”(还有其他替代方案),主要从源代码构建其依赖项以及应用程序,以生成最终二进制文件。它们甚至可能强制应用程序的链接,使用静态链接以简化操作。
Rust 和 Go 可以采用这种方法,因为这些语言中的项目比 C 和 C++ 中的项目小几个数量级,并且分发这些语言的二进制文件(如专有组件)仍然不是一件常见的事情。但是,正如我们所说,C 和 C++ 项目规模庞大,因此管理二进制文件和处理 ABI 兼容性绝对是必要的。
C 和 C++ 构建
首先,让我们了解一下 C 和 C++ 构建过程。例如,源代码如何编译成静态或共享库中的原生代码,它们如何链接,预处理器如何工作等等。与其仅仅解释它,不如用一个简单的场景来说明这些问题。让我们构建一个名为“math2”的库,使用以下文件实现
//math2.h
# pragma once
int add(int a, int b);
//math2.cpp
#include "math2.h"
int add(int a, int b){
return a + b;
}
将其构建为静态库(在 Ubuntu 16、gcc 5.4、CMake 静态库、Release 模式下),我们得到以下代码(objdump -d libmath2.a)
0000000000000000 <_Z3addii>:
0: 8d 04 37 lea (%rdi,%rsi,1),%eax
3: c3 retq
我们可以看到两个整数的add函数addii,而lea操作只不过是一个巧妙的(更快的)加法。
现在让我们为 3D 操作创建另一个库,称为“math3”,其源代码如下
//math3.h
# pragma once
int add3(int a, int b, int c);
//math3.cpp
#include "math3.h"
#include "math2.h"
int add3(int a, int b, int c){
return add(add(a, b), c);
}
将其构建为静态库,我们得到(objdump -d -x libmath3.a)
0000000000000000 <_Z4add3iii>:
0: 53 push %rbx
1: 89 d3 mov %edx,%ebx
3: e8 00 00 00 00 callq 8 <_Z4add3iii+0x8>
4: R_X86_64_PC32 _Z3addii-0x4
8: 89 de mov %ebx,%esi
a: 89 c7 mov %eax,%edi
c: 5b pop %rbx
d: e9 00 00 00 00 jmpq 12 <_Z4add3iii+0x12>
e: R_X86_64_PC32 _Z3addii-0x4
现在让我们修改math2的add函数,例如
int add(int a, int b){
return a + b + 1;
}
我们将为math2.lib获得不同的机器代码
0000000000000000 <_Z3addii>:
0: 8d 44 37 01 lea 0x1(%rdi,%rsi,1),%eax
4: c3 retq
但是检查 math3.lib,我们可以看到它完全相同的代码,根本没有改变!
但是,如果我们更改库类型,并改为构建 math3.so 共享库,我们将获得的机器代码将是
0000000000000660 <_Z4add3iii>:
660: 53 push %rbx
661: 89 d3 mov %edx,%ebx
663: e8 d8 fe ff ff callq 540 <_Z3addii@plt>
668: 89 de mov %ebx,%esi
66a: 89 c7 mov %eax,%edi
66c: 5b pop %rbx
66d: e9 ce fe ff ff jmpq 540 <_Z3addii@plt>
672: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
679: 00 00 00
67c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000000680 <_Z3addii>:
680: 8d 44 37 01 lea 0x1(%rdi,%rsi,1),%eax
684: c3 retq
我们可以清楚地看到,math2.a 静态库的代码已被“嵌入”到共享库中,因此它基本上包含了 math2.a 静态库中存在的机器代码的副本。如果math2库源代码发生更改,并且所有内容都重新构建,则math3.so机器代码将不同。
此问题不仅适用于链接到共享库中的静态库中的编译代码。相同的问题也发生在头文件中。如果我们将 math2 更改为仅头文件库,在math2.h中实现
# pragma once
int add(int a, int b){
return a + b;
}
然后,构建静态库math3.lib将导致
0000000000000000 <_Z3addii>:
… # irrelevant
0000000000000010 <_Z4add3iii>:
10: 8d 04 37 lea (%rdi,%rsi,1),%eax
13: 01 d0 add %edx,%eax
15: c3 retq
头文件由预处理器包含在使用者编译单元中,因此问题在于,在这种情况下,math2 的最终机器代码也被嵌入/复制到 math3 的二进制工件中。即使add函数已嵌入二进制文件中,add3的实现实际上已内联了add函数。在实践中,上述代码很容易破坏“单一定义规则”,因此通常会发现它被显式内联
inline int add(int a, int b){
return a + b;
}
无论如何,内联只是对编译器的建议,即使未声明,它也可以执行内联,或者甚至可以忽略它。此外,编译器可以在链接时跨二进制工件边界使用“全程序优化”或“链接时代码生成”积极地进行内联。但问题仍然相同,在“math2”组件中所做的任何更改都会导致“math3”组件的二进制文件发生更改。
C/C++ 构建系统能够缓存编译结果并在源代码更改上应用逻辑以有效地执行增量构建,跳过不需要重新构建的内容。不幸的是,这些技术适用于同一项目内的构建,因此如果代码在不同项目之间重用,则无法轻松应用它们。此外,这种方法对于持续集成来说还不够。
C/C++ 中的二进制管理
上一节中描述的内容对于使用 C 和 C++ 的 DevOps 来说同样重要。这是因为,**即使 C/C++ 编译的二进制工件的源代码根本没有改变,它也可能发生改变。**
此问题不仅与代码依赖性有关,而且与系统和开发配置广泛相关。原生代码在不同的操作系统中是不同的,而且不同的编译器将从相同的源代码生成不同的二进制文件。即使同一编译器的不同编译器版本也会从相同的源代码生成不同的二进制文件,因为编译器技术在不断发展,并且能够进一步优化代码。此外,可以从相同的源代码生成不同的工件,正如我们上面看到的,我们可以将同一个库构建为静态库或共享库,它们肯定将导致不同的二进制工件。
在某些(极端)情况下,如果 C/C++ 项目是单平台的,并且开发工具在组织内完全固定和冻结,则可以假设源代码和编译的二进制文件之间存在一对一的对应关系。这在某种程度上类似于 Java 的“一次构建,随处运行”的理念。但是对于使用原生代码的语言来说,情况并非如此。例如,当 Python 包包含原生扩展时,很难管理它们,需要在安装时从源代码构建(并需要编译器,这对许多 Python 开发人员来说都是一个不便),或者其他困难的过程。Python-wheels (http://pythonwheels.com/) 通过为同一个源包提供不同的二进制包以及命名约定来改善了这个问题。
需要一个能够有效管理来自同一源代码的不同二进制文件的有效 DevOps 流程。
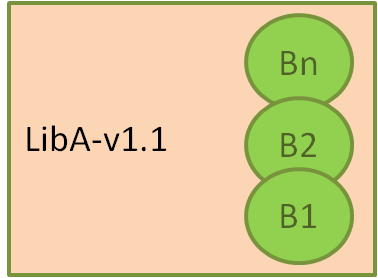
在这里,我们表示我们的系统,其中我们有一个组件或包,称为 LibA,其源代码版本为 1.1。已构建并存储了来自同一源代码的多个二进制文件,称为 B1…Bn。例如,对于不同的操作系统,例如 Windows、Linux 和 OSX。
这将是任何系统的常见模式。例如,Conan C/C++ 包管理器使用配方从同一源代码构建不同的二进制文件,所有这些二进制文件都可以上传并一起存储在 Conan 远程服务器(conan_server 或 Artifactory)中的同一个引用下。
C/C++ 的持续集成问题
项目之间重用代码的需求,以及解决复杂性并处理 C/C++ 项目规模庞大的需求,都需要对组件进行“组件化”或“打包”。众所周知的分治模式。
此类组件的问题在于,它们不再属于同一个项目。事实上,它们可以(而且通常确实)具有不同的构建系统,因此无法为后续的增量构建缓存编译结果。此外,已建立的持续集成最佳实践之一是从头开始在干净的环境中尽可能多地构建完整构建,以确保可重复性和避免“在我的机器上可以工作”的问题。
让我们继续举例说明。假设我们的 Jenkins 持续集成系统中有以下组件,主要是库和可执行文件以简化说明,但组件也可以是库组或其他工件或数据。为了简单起见,我们假设对于所有这些组件,系统都只为一个平台构建了一个二进制文件
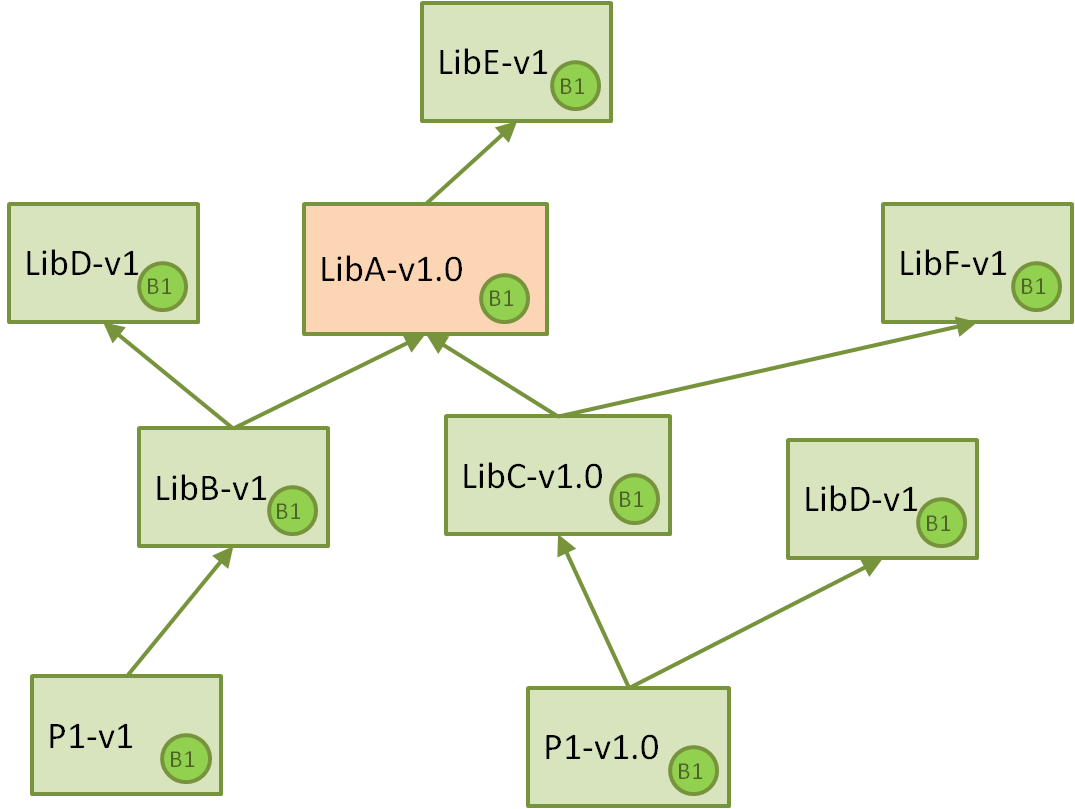
因此,我们有两个项目,每个项目都构建一个最终应用程序,将其部署到某个地方。这些项目依赖于不同的库,特定的版本,其中一些可以在项目之间共享,而另一些则不能。
现在,假设在 LibA 中检测到了一些性能问题,那么开发人员会克隆 LibA 的仓库,优化代码并提高性能。由于这不是一个重大更改,因此将版本提升到 1.1,并推送仓库,从而触发 CI 作业并创建一个新的软件包。
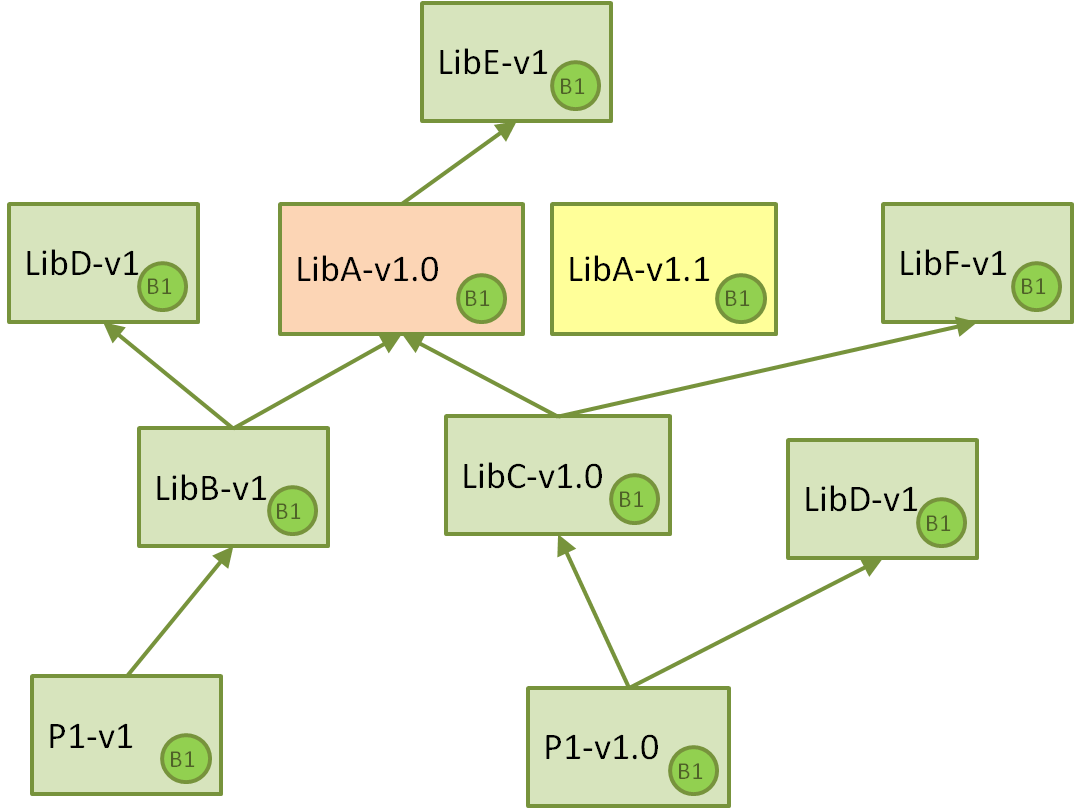
执行此任务的 Jenkins CI 作业应该不会有什么大问题。但是,现在重要的是,我们希望错误修复能够向下游传播,最终创建项目应用程序的新版本。这就是挑战开始的地方。
我们必须回答的第一个问题是,是否应该在 CI 中自动向下游传播此类版本。这当然意味着以适当的顺序触发依赖包的构建。总的来说,这听起来像是一种麻烦的方法,很容易导致问题并导致 CI 服务器不必要的饱和。
首先,让我们确定一个手动流程。团队决定 LibC-v1.0 现在应该使用最新的 LibA-v1.1,因此他们克隆了 LibC 仓库,将依赖项提升到 LibA,将其自身版本增加到 LibC-v1.1 并推送更改,从而由 Jenkins CI 作业创建了一个具有新二进制文件的新软件包。
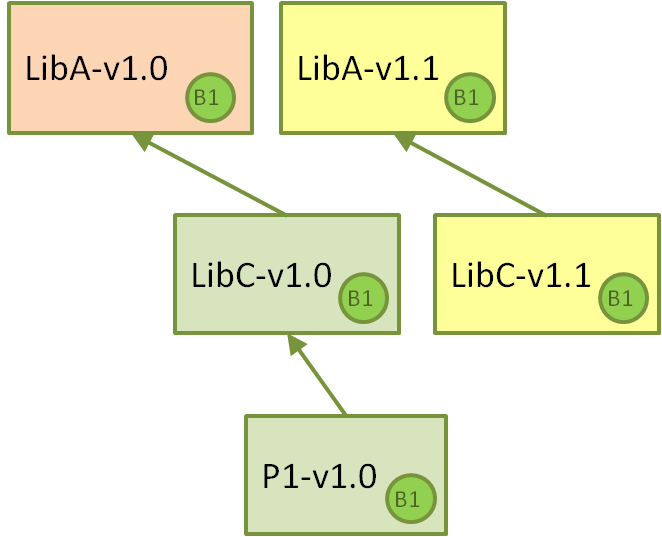
这确实有效,并且可以完成。对于包含构建元数据的版本控制方案,它可能是有意义的,但对于其他方案来说则不方便。然后出现了一个重要的问题
“为什么应该增加 LibC 的版本?代码本身没有任何实际更改。我们只是使用了依赖项的新版本。但如上所示,这可能会也可能不会更改生成的二进制文件,因此可能不需要创建新的软件包并构建新的二进制文件!”
确实如此,一个高效的包管理和 CI 系统应该能够应对这种情况。为了实现这一目标,需要定义两件事
- **重新构建逻辑**: 在
LibC中定义某些逻辑的能力,即当其依赖项发生变化时,它是否需要构建新的二进制文件。 - **依赖项重新定义**: 创建
LibC新二进制文件的能力,该文件具有与其声明中不同的依赖项。
重新构建逻辑:语义化版本控制无济于事
乍一看,并且根据我们从其他语言中获得的经验,我们可能会倾向于说第一个问题将由语义化版本 (semver) 回答。但是,请记住上面一部分内容:**即使对组件的私有实现进行小的、兼容的更改,也可能意味着其依赖项的二进制文件发生更改。**
这里唯一可能的策略是让开发人员定义它,这就是 Conan C/C++ 包管理器的方法。它允许定义一个 package_id() 方法,该方法可以指定它对每个依赖项自身二进制文件的影响。语义化版本控制对于没有更改公共头文件的静态-静态链接来说是一个选项,但对于共享-静态链接,依赖项二进制文件中的每个更改都需要为其构建新的二进制文件。可以有条件地执行此操作,使软件包能够构建共享和静态二进制文件,每个二进制文件都遵循其自己的重新构建逻辑。
依赖项重新定义
手动流程是在软件包中手动增加依赖项版本。但是,如果软件包在某个地方被哈希或版本化,这肯定会改变当前的软件包,并且这种更改可能会产生后果。例如,软件包中的更改可能会触发 CI 作业以重新构建该软件包。
这里的目标是能够重新定义 LibC-v1.0 拥有的 LibA-v1.0 版本,而无需修改 LibC 本身。为此,有两种策略
- **版本范围**。
LibC而不是声明对LibA-v1.0的“硬编码”依赖关系,它可以声明一个版本范围,例如依赖于LibA-v1.X。这种方法可能有一些限制不便之处,例如依赖于范围LibA-v1.[0-3]并且还需要依赖于新的LibA-v1.4。 - **版本覆盖**。这与 Maven 的方法相同。您可以声明您希望在下游使用的版本,并且此指定的版本将覆盖任何其他上游声明的版本。
使用这种方法的结果将是以下之一
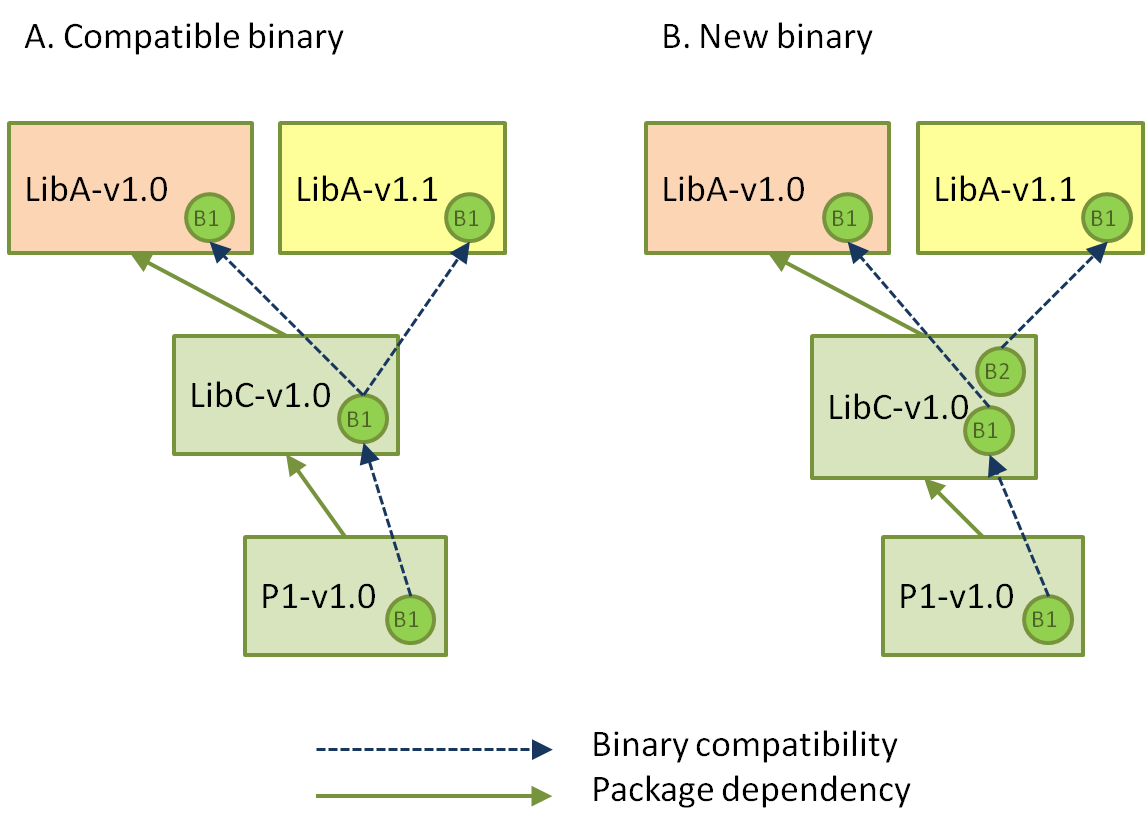
在方案 A 中,LibC-v1.0 与 LibA-v1.[0, 1] 均兼容,并且无需为此构建新的二进制文件。这可能是静态库的情况,并且 LibA 中的次要版本增加并不意味着公共头文件中的更改。在情况 B 中,需要为 LibC 创建新的二进制文件。这可能是 LibA 是仅包含头文件的库,或者 LibC 是共享库的情况。
自动传播
此过程可以向下游重复,指示软件包在必要时进行构建。但必须尊重图的顺序,否则,某些二进制文件可能无法使用最新的上游版本正确构建。
这就是在 CI 过程中自动执行此操作很有趣的地方。我们已经放弃了在 LibA 的新版本之后自动升级所有下游内容的过程,因此该过程应从下游触发。
一个过程可以在消费项目(例如 P1)中直接定义对 LibA-v1.1 的覆盖依赖项,并让此依赖项向上游传播,要求中间的每个节点在必要时构建新的兼容二进制文件。对于多配置项目(多平台或使用不同设置编译),这就像深度优先搜索方法一样,对于每个配置(编译器、版本、设置),图中的软件包都将被构建。
但是,我们可能希望在继续向下游传播之前,根据需要正确构建和测试每个软件包,可能对于许多配置都是如此。包管理器应该告诉 CI 系统的第一个问题是哪些依赖项涉及其中。问题可能是
“鉴于 LibA 已升级,在项目 P1 也升级的情况下,应检查哪些软件包以确定是否需要新的二进制文件?”
答案应该是 [LibC-v1.0, P1-v1.0] 的有序列表。
可以使用此列表触发一系列(尊重顺序的)CI 作业,每个作业根据需要为每个软件包构建新的二进制文件。每个作业都可能应用于每个软件包的依赖项覆盖,或具有定义的版本范围以及重新构建信息。
结论
DevOps 中,特别是 C 和 C++ 项目的持续集成中存在许多开放的挑战。Conan 包管理器实现了这个难题中的一些必要部分
- 它可以为相同的源代码和相同的软件包配方构建和管理许多不同的二进制文件,并将二进制文件托管在 conan_server 或 Artifactory 中。
- 它可以通过
package_id()方法定义重新构建逻辑,这是定义软件包的不同配置以及影响二进制文件的依赖项的方式。 - 它提供依赖项管理,包括版本覆盖、冲突解决和版本范围。这允许在依赖项中传播软件包更改,而无需实际编辑软件包配方,只需为不同的依赖项生成不同的二进制文件。
- 它提供依赖项构建顺序的信息(
conan info --build-order命令)。可以查询任何软件包的此信息,这将是更改上游时处理软件包的顺序。
但是,这些仅仅是部分内容。我们正在努力改进这些 CI 工具,并且绝对需要您的反馈!以下是一些我们希望从您那里获得反馈的问题
- 手动方法在您的 CI 流程中是否有意义?您是否更愿意生成新的软件包,并在您的配方中提升依赖项的版本?
- 如果不是,您希望采用哪种方法?根据需要为整个项目构建二进制文件,还是更多地采用每个软件包的方法构建?
- 您更喜欢使用依赖项覆盖还是版本范围?
请向我们提供您可能对 C 和 C++ 项目中的 DevOps 和 CI 产生的任何想法、建议和反馈,我们将继续为 C 和 C++ 社区提供尽可能好的工具。